Probability and Random Variable

You may have heard of Schrödinger’s cat mentioned in a thought experiment in quantum physics. Briefly, according to the Copenhagen interpretation of quantum mechanics, the cat in a sealed box is simultaneously alive and dead until we open the box and observe the cat. The macrostate of cat (either alive or dead) is determined at the moment we observe the cat. Although not directly applicable, I think the indeterminacy of macrostate in quantum mechanics has some analogy to random variable in probability theory in that the value (\(x\)) of the random (\(X\)) is determined at the moment the random is observed and we say \(x\) is the realization of \(X\).
Multinomial Distribution and Dirichlet Distribution
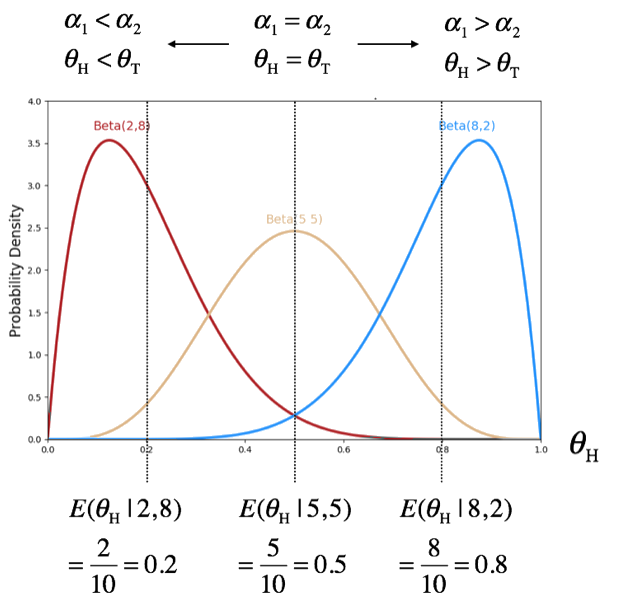
You may remember that Bayesian probability is a belief. We can numerically express our belief using the beta distribution. For example, if we believe a coin is balanced, our belief on this coin’s parameter (\(\theta_T = \theta_H\)) can be expressed using two parameters (\(\alpha_T = \alpha_H\)) of beta distribution such that the expected value of beta RV is \(E(\theta_H|\alpha_1, \alpha_2) = 0.5\).